Lý thuyết Tin học 12 Bài 3 (Cánh diều): Giới thiệu về khoa học dữ liệu (Tiếp theo)
Tóm tắt lý thuyết Tin học lớp 12 Bài 3: Giới thiệu về khoa học dữ liệu (Tiếp theo) hay, chi tiết sách Cánh diều sẽ giúp học sinh nắm vững kiến thức trọng tâm, ôn luyện để học tốt Tin học 12.
Lý thuyết Tin học 12 Bài 3: Giới thiệu về khoa học dữ liệu (Tiếp theo)
1. Các đặc trưng của dữ liệu lớn
Dữ liệu lớn (Big Data):
- Định nghĩa: Dữ liệu lớn là nguồn dữ liệu có khối lượng rất lớn, tính đa dạng và phức tạp, khó xử lý bằng công cụ truyền thống.
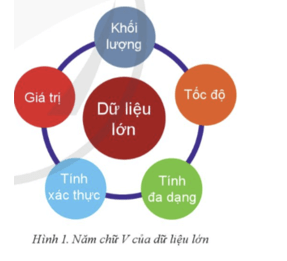
- Đặc trưng (5 chữ V):
+ Khối lượng (Volume): Dữ liệu có thể đạt nhiều petabyte hoặc exabyte. Ví dụ: Dữ liệu về khách hàng của một doanh nghiệp lớn.
+ Tốc độ (Velocity): Dữ liệu được tạo ra nhanh chóng và cần xử lý theo thời gian thực. Ví dụ: Dữ liệu từ thiết bị cảm biến và mạng xã hội.
+ Tính đa dạng (Variety): Dữ liệu đến từ nhiều nguồn và dưới nhiều dạng như văn bản, hình ảnh, âm thanh. Ví dụ: Dữ liệu từ Facebook.
+ Tính xác thực (Veracity): Đề cập đến độ tin cậy và chính xác của dữ liệu. Quan trọng để đảm bảo hiểu biết từ dữ liệu là chính xác.
+ Giá trị (Value): Dữ liệu lớn có tiềm năng tạo ra thông tin giá trị cho quyết định. Ví dụ: Dự án Bộ gen người HGP.
- Thách thức: Quản lý và khai thác dữ liệu lớn có nhiều thách thức về lưu trữ, xử lý, và đảm bảo chất lượng dữ liệu.
2. Phân tích dữ liệu, phát hiện tri thức
a) Phân tích dữ liệu:
Phân tích dữ liệu là quá trình kiểm tra, làm sạch, chuyển đổi và lập mô hình dữ liệu để tìm ra thông tin hữu ích cho kết luận hoặc dự đoán. Phân tích dữ liệu được chia thành hai loại:
- Phân tích mô tả: Tóm tắt dữ liệu quá khứ và trình bày trực quan để người sử dụng dễ dàng nắm bắt thông tin quan trọng. Thông tin được biểu diễn bằng sơ đồ, biểu đồ, đồ thị,... giúp nhận ra các mẫu hoặc xu hướng, cung cấp cái nhìn tổng thể về vấn đề.
- Phân tích dự đoán: Nhằm đưa ra dự đoán hoặc phân loại dữ liệu mới.
b) Khai phá dữ liệu, phát hiện tri thức:
Khai phá dữ liệu là một bước trong quy trình phát hiện tri thức, nhằm phát hiện các mẫu và xu hướng trong tập dữ liệu. Quy trình phát hiện tri thức bao gồm toàn bộ việc trích xuất tri thức từ dữ liệu. Khai phá dữ liệu thường sử dụng các phương pháp giao thoa giữa học máy và thống kê. Các kĩ thuật khai phá dữ liệu khác nhau, như phân loại và phân cụm, giúp trích xuất thông tin hữu ích từ các tập dữ liệu lớn.
3. Vai trò của máy tính và thuật toán ưu việt với Khoa học dữ liệu
a) Máy tính là công cụ quan trọng trong Khoa học dữ liệu:
Vai trò của máy tính và thuật toán ưu việt với Khoa học dữ liệu
- Tạo dữ liệu lớn: Mạng xã hội, thiết bị di động, cảm biến đã tạo ra lượng lớn dữ liệu hàng ngày.
- Công cụ thiết yếu: Máy tính và thiết bị số lưu trữ và xử lý dữ liệu hiệu quả, thúc đẩy sự phát triển của Khoa học dữ liệu.
- Phân tích dữ liệu: Trước đây, chuyên gia thực hiện phân tích dữ liệu; hiện nay, máy tính đóng vai trò quan trọng trong việc xử lý và phân tích dữ liệu.
- Giai đoạn dự án: Máy tính hỗ trợ trong các giai đoạn như thu thập, chuẩn bị và phân tích dữ liệu.
- Khả năng lưu trữ: Máy tính cung cấp khả năng lưu trữ và quản lý dữ liệu hiệu quả.
- Trí tuệ nhân tạo và Học máy: Phát triển các công cụ và thuật toán để mô hình hóa dữ liệu và tự động phát hiện tri thức.
- Nghề nghiệp: Nhà khoa học dữ liệu được xếp hạng cao trong các nghề công nghệ và dự đoán tăng trưởng việc làm cao trong tương lai.
b) Máy tính và thuật toán ưu việt giúp phân tích dữ liệu hiệu quả:
- Phần mềm phân tích dữ liệu: Máy tính chạy phần mềm để mô hình hóa và phát hiện tri thức trong dữ liệu, giúp chuyên gia phát hiện vấn đề và đề xuất giải pháp.
- Siêu máy tính: Có tốc độ hàng nghìn tỉ phép tính/giây và bộ nhớ lớn, giúp quản lý và phân tích dữ liệu lớn hiệu quả.
- Điện toán đám mây: Cho phép lưu trữ và truy cập dữ liệu lớn mọi lúc mọi nơi, tiết kiệm chi phí cơ sở hạ tầng và linh hoạt trong mở rộng hoặc thu hẹp tài nguyên. Ví dụ: Amazon Web Services, Microsoft Azure.
- Cơ sở dữ liệu NoSQL: Phù hợp với dữ liệu không cấu trúc, cho phép lưu trữ linh hoạt và dễ mở rộng. Ví dụ: Amazon DynamoDB, Google MongoDB, Apache Hadoop.
- Máy tính cụm: Tập hợp nhiều máy tính hoạt động như một máy tính duy nhất, có tính sẵn sàng cao, dễ quản lý và tiết kiệm chi phí.
- Thuật toán song song: Thực hiện nhiều phép tính đồng thời, giúp xử lý dữ liệu lớn nhanh chóng và hiệu quả.
Xem thêm các chương trình khác:
- Soạn văn 12 Cánh diều (hay nhất)
- Văn mẫu 12 - Cánh diều
- Tóm tắt tác phẩm Ngữ văn 12 – Cánh diều
- Tác giả tác phẩm Ngữ văn 12 - Cánh diều
- Bố cục tác phẩm Ngữ văn 12 – Cánh diều
- Nội dung chính tác phẩm Ngữ văn 12 – Cánh diều
- Giải sgk Toán 12 – Cánh diều
- Giải Chuyên đề học tập Toán 12 – Cánh diều
- Lý thuyết Toán 12 – Cánh diều
- Giải sbt Toán 12 – Cánh diều
- Giải sgk Tiếng Anh 12 - ilearn Smart World
- Trọn bộ Từ vựng Tiếng Anh lớp 12 ilearn Smart World đầy đủ nhất
- Trọn bộ Ngữ pháp Tiếng Anh lớp 12 ilearn Smart World đầy đủ nhất
- Giải sbt Tiếng Anh 12 – iLearn Smart World
- Giải sgk Vật lí 12 – Cánh diều
- Giải Chuyên đề học tập Vật lí 12 – Cánh diều
- Lý thuyết Vật lí 12 – Cánh diều
- Giải sbt Vật lí 12 – Cánh diều
- Giải sgk Hóa học 12 – Cánh diều
- Giải Chuyên đề học tập Hóa 12 – Cánh diều
- Lý thuyết Hóa 12 – Cánh diều
- Giải sbt Hóa 12 – Cánh diều
- Giải sgk Sinh học 12 – Cánh diều
- Giải Chuyên đề học tập Sinh học 12 – Cánh diều
- Lý thuyết Sinh học 12 – Cánh diều
- Giải sbt Sinh học 12 – Cánh diều
- Giải sgk Lịch sử 12 – Cánh diều
- Giải Chuyên đề học tập Lịch sử 12 – Cánh diều
- Giải sbt Lịch sử 12 – Cánh diều
- Giải sgk Địa lí 12 – Cánh diều
- Giải Chuyên đề học tập Địa lí 12 – Cánh diều
- Giải sbt Địa lí 12 – Cánh diều
- Giải sgk Công nghệ 12 – Cánh diều
- Giải sgk Kinh tế pháp luật 12 – Cánh diều
- Giải Chuyên đề học tập Kinh tế pháp luật 12 – Cánh diều
- Giải sbt Kinh tế pháp luật 12 – Cánh diều
- Giải sgk Giáo dục quốc phòng 12 – Cánh diều
- Giải sgk Hoạt động trải nghiệm 12 – Cánh diều